In-Depth Summary of Apache Kafka
Guidelines on how to achieve real-time data and stream processing at scale
Meet Kafka
How we move the data becomes nearly as important as the data itself. Publish/subscribe messaging is a pattern that is characterized by the senders (publishers) of a piece of data (message) and consumers of the message that are loosely decoupled from each other. Pub/sub systems like Kafka are often designed with the help of an intermediary broker to orchestrate this pattern to enable diverse use cases.

A message is simply an array of bytes as far as Kafka is concerned, so the data contained within it does not have a specific format or meaning to Kafka. A message can have an optional bit of metadata, which is referred to as a key. Keys are used when messages are to be written to partitions in a more controlled manner. For efficiency, messages are written into Kafka in batches. A batch is just a collection of messages, all of which are being produced to the same topic and partition to avoid individual roundtrips across the network for each message. Of course, this is a tradeoff between latency and throughput.
It is recommended that additional structure, or schema, be imposed on the message content so that it can be easily understood. Simplistic systems, such as JSON and XML are easy to use and human-readable. However, they lack features such as robust type handling and compatibility between schema versions. Apache Avro, which is a serialization framework originally developed for Hadoop provides a compact serialization format; schemas that are separate from the message payloads and that do not require code to be generated when they change; and strong data typing and schema evolution, with both backward and forward compatibility. Schemas are usually stored in a common repository to share.
Messages in Kafka are categorized into topics. Topics are additionally broken down into a number of partitions. There is no guarantee of message time-ordering across the entire topic, just within a single partition. Partitions are also the way that Kafka provides redundancy and scalability. Each partition can be hosted on a different server, which means that a single topic can be scaled horizontally across multiple servers. Most often, a stream is considered to be a single topic of data, regardless of the number of partitions.
Kafka clients are users of the system, and there are two basic types: producers and consumers.
- The producer creates new messages for a specific topic. By default, the producer does not care what partition a specific message is written to and will balance messages over all partitions of a topic evenly. In some cases, the producer will direct messages to specific partitions by using the message key and a partitioner that will generate a hash of the key and map it to a specific partition. Kafka is able to seamlessly handle multiple producers that are using many topics or the same topic.
- The consumer subscribes to one or more topics and reads the messages. The consumer keeps track of which messages it has already consumed by keeping track of the offset of messages. The offset is another bit of metadata — an integer value that continually increases — that Kafka adds to each message as it is produced. Each message in a given partition has a unique offset. By storing the offset of the last consumed message for each partition, a consumer can stop and restart without losing its place. Consumers work as part of a consumer group, which is one or more consumers that work together to consume a topic. The group assures that each partition is only consumed by one member. The mapping of a consumer to a partition is often called ownership of the partition by the consumer. In this way, consumers can horizontally scale to consume topics with a large number of messages. Additionally, if a single consumer fails, the remaining members of the group will rebalance the partitions being consumed to take over for the missing member. Kafka is also designed for multiple consumers to read any single stream of messages without interfering with each other.

- The broker receives messages from producers, assigns offsets to them, and commits the messages to storage on disk. It also services consumers, responding to fetch requests for partitions and responding with the messages that have been committed to disk. Depending on the specific hardware and its performance characteristics, a single broker can easily handle thousands of partitions and millions of messages per second.
Kafka brokers are designed to operate as part of a cluster. Within a cluster of brokers, one broker will also function as the cluster controller (elected automatically from the live members of the cluster). The controller is responsible for administrative operations, including assigning partitions to brokers and monitoring for broker failures. A partition is owned by a single broker in the cluster, and that broker is called the leader of the partition. A partition may be assigned to multiple brokers, which will result in the partition being replicated. This provides redundancy of messages in the partition, such that another broker can take over leadership if there is a broker failure. However, all consumers and producers operating on that partition must connect to the leader.
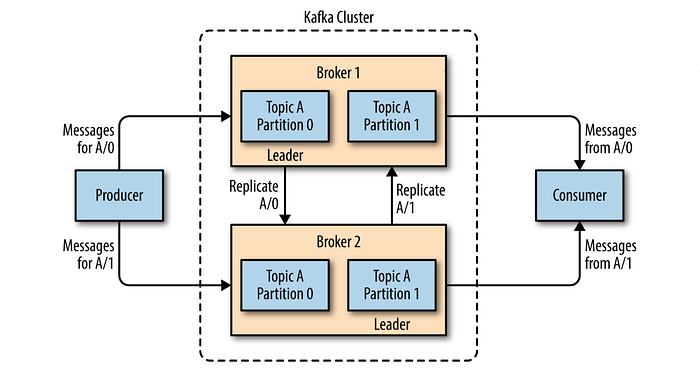
A key feature of Apache Kafka is that of retention, which is the durable storage of messages for some period of time. Kafka brokers are configured with a default retention setting for topics, either retaining messages for some period of time (e.g., 7 days) or until the topic reaches a certain size in bytes (e.g., 1 GB). Individual topics can also be configured with their own retention settings so that messages are stored for only as long as they are useful. Topics can also be configured as log compacted, which means that Kafka will retain only the last message produced with a specific key. Durable retention means that if a consumer falls behind, either due to slow processing or a burst in traffic, there is no danger of losing data. This allows them to restart and pick up processing messages where they left off with no data loss.
As Kafka deployments grow, it is often advantageous to have multiple clusters. There are several reasons why this can be useful: Segregation of data types, isolation due to security requirements and the utilization of multiple data-centers (for proximity and disaster recovery). When working with multiple data-centers in particular, it is often required that messages be copied between them. The Kafka project includes a tool called MirrorMaker, used for this purpose.
Kafka’s flexible scalability makes it easy to handle any amount of data. Users can start with a single broker as a proof of concept. Expansions can be performed while the cluster is online, with no impact on the availability of the system as a whole. This also means that a cluster of multiple brokers can handle the failure of an individual broker, and continue servicing clients. Clusters that need to tolerate more simultaneous failures can be configured with higher replication factors.
All of these features come together to make Apache Kafka a publish/subscribe messaging system with excellent performance under high load.
Kafka was created to address the data pipeline problem at LinkedIn. It was designed to provide a high-performance messaging system that can handle many types of data and provide clean, structured data about user activity and system metrics in real time.
Apache Zookeeper is used by Kafka for storing metadata for the brokers. Apache Zookeeper is a Java application, and can run on many operating systems.
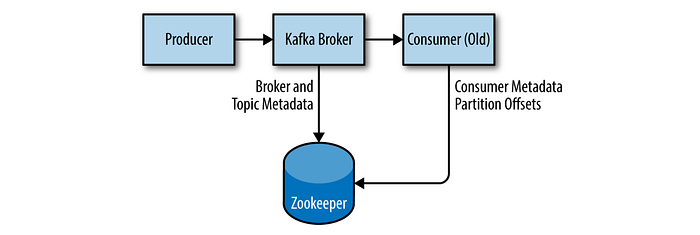
A Zookeeper cluster is called an ensemble. Due to the algorithm used, it is recommended that ensembles contain an odd number of servers (e.g., 3, 5, etc.) as a majority of ensemble members (a quorum) must be working in order for Zookeeper to respond to requests. It is also not recommended to run more than seven nodes, as performance can start to degrade due to the nature of the consensus protocol.
There are several broker configurations that should be reviewed when deploying Kafka for any environment other than a standalone broker on a single server. Every Kafka broker must have an integer identifier, which is set by using the broker id configuration. It is also best to specify multiple Zookeeper servers (which are all part of the same ensemble) in broker configuration that allows the Kafka broker to connect to another member of the Zookeeper ensemble in the event of server failure. Kafka persists all messages to disk, and these log segments are stored in the directories specified in the log.dirs configuration. The broker will store partitions on them in a “least-used” fashion with one partition’s log segments stored within the same path. Kafka uses a configurable pool of threads for handling log segments. The default Kafka configuration specifies that the broker should automatically create a topic when a producer starts writing messages to the topic, a consumer starts reading messages from the topic or any client requests metadata for the topic. This behaviour can be disabled.
The Kafka server configuration specifies many default configurations for topics that are created. The num.partitions parameter determines how many partitions a new topic is created with. Keep in mind that the number of partitions for a topic can only be increased, never decreased. Many users will have the partition count for a topic be equal to, or a multiple of, the number of brokers in the cluster. This allows the partitions to be evenly distributed to the brokers, which will evenly distribute the message load. There are several factors to consider when choosing the number of partitions: What is the throughput you expect to achieve for the topic? If you are sending messages to partitions based on keys, adding partitions later can be very challenging. Consider the number of partitions you will place on each broker and available disk space and network bandwidth per broker. Avoid overestimating, as each partition uses memory and other resources on the broker and will increase the time for leader elections.
Kafka Producers: Writing Messages to Kafka
Whether you use Kafka as a queue, message bus, or data storage platform, you will always use it with a producer that writes data, a consumer that reads data, or an application that serves both roles.
Messages are produced by creating a producer record, which must include the topic we want to send the record to and a value. Optionally, we can also specify a key and/or a partition. Once the record is sent, the first thing the producer will do is to serialize the key and value objects to byte array so they can be sent over the network. Next, the data is sent to a partitioner if a partition is not specified. There is a separate thread batching the produced messages for the same topic and partition. If messages are sent successfully, a record metadata is returned back having the topic, partition, and the offset of the record within the partition. If the broker failed to write the messages, it will return an error. When the producer receives an error, it may retry sending the message a few more times before giving up and returning an error.
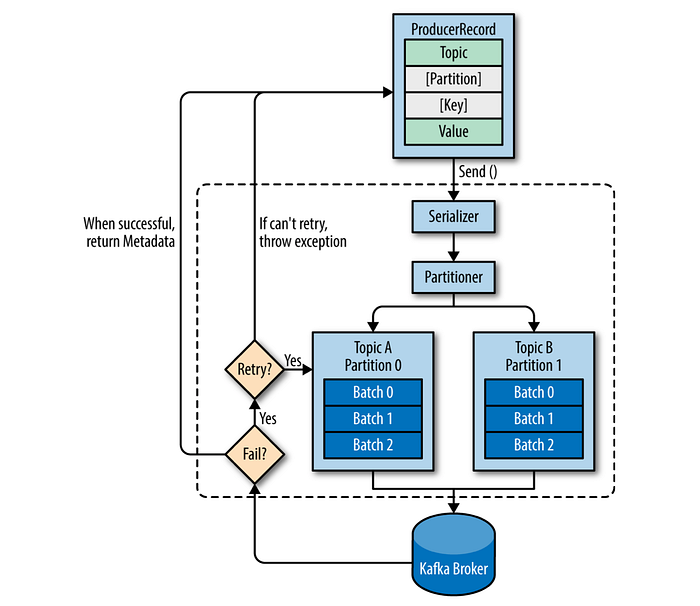
There are three primary methods of sending messages:
- Fire-and-forget: We send a message to the server and don’t really care if it arrives successfully or not. Most of the time, it will arrive successfully, however some messages will get lost using this method.
- Synchronous send: We send a message, the send() method returns a Future object, and we use get() to wait on the future and see if the send() was successful or not.
- Asynchronous send: We call the send() method with a callback function, which gets triggered when it receives a response from the Kafka broker that lets you to handle errors as well.
A producer object can be used by multiple threads to send messages. You will probably want to start with one producer and one thread. If you need better throughput, you can add more threads that use the same producer. Once this ceases to increase throughput, you can add more producers to the application to achieve even higher throughput.
We may get an exception if the producer encountered errors before sending the message to Kafka. Those can be a SerializationException when it fails to serialize the message, a BufferExhaustedException or TimeoutException if the buffer is full, or an InterruptException if the sending thread was interrupted. Producer has two types of errors. Retriable errors are those that can be resolved by sending the message again. For example, a connection error can be resolved because the connection may get reestablished. A “no leader” error can be resolved when a new leader is elected for the partition. Producer can be configured to retry those errors automatically, so the application code will get retriable exceptions only when the number of retries was exhausted and the error was not resolved. Some errors will not be resolved by retrying. For example, “message size too large.” In those cases, Producer will not attempt a retry and will return the exception immediately.
Configuring Producers
- Configuring acknowledgements for the reliable delivery of messages is possible, or also best-effort (not reliable), which is not expecting acks, is providing high throughput.
- Buffer memory size is important to preserve ensued message waiting for delivery, and it’s possible to configure a timeout for blocking on buffer’s availability.
- By enabling compression, you reduce network utilization and storage.
- Control how many times the producer will retry sending the message before giving up and notifying the client of an issue, and also backoff duration in between retries.
- Set the batch size in bytes to a high number to avoid separate writes for the same partition, however, this does not mean that the producer will wait for the batch to become full.
- The linger duration in ms controls the amount of time to wait for additional messages before sending the current batch (or sent immediately in default).
- If the order of messages is not a concern, the throughput can be increased by increasing the number of in-flight requests per connection (how many messages the producer will send to the server without receiving responses), however the throughput will start decreasing once this number makes the batching less efficient.
- The request timeout durations while waiting for a reply (that can cause retries) can be configured for both producers and brokers, and also the max blocking time for send calls not returning i.e. due to full buffer.
- You can control the size of a request sent by the producer. It caps both the size of the largest message that can be sent and the number of messages that the producer can send in one request.
- It is a good idea to increase the TCP send and receive buffers used by the sockets when producers or consumers communicate with brokers in a different datacenter because those network links typically have higher latency and lower bandwidth.
Serializers let us control the format of the events we write to Kafka. The producer configuration includes mandatory serializers, and it is possible to use the default String serializer. Kafka also includes serializers for integers and ByteArrays, but this does not cover most use cases. Eventually, you will want to be able to serialize more generic records. Avro is one of many ways to serialize events, but one that is very commonly used with Kafka.
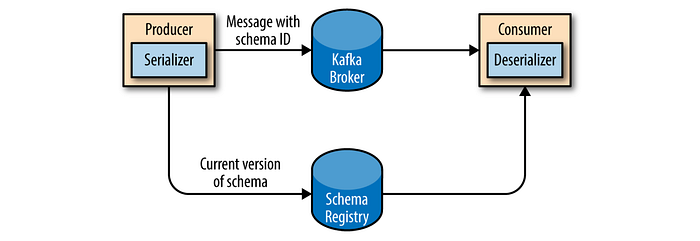
If a key exists and the default partitioner is used, Kafka will hash the key, and use the result to map the message to a specific partition. Since it is important that a key is always mapped to the same partition, we use all the partitions in the topic to calculate the mapping — not just the available partitions. The mapping of keys to partitions is consistent only as long as the number of partitions in a topic does not change. When partitioning keys is important, the easiest solution is to create topics with sufficient partitions and never add partitions. However, Kafka does not limit you to just hash partitions, and sometimes there are good reasons to partition data differently. In these cases, you can implement a custom partitioning strategy.
Kafka Consumers: Reading Data from Kafka
Kafka consumers subscribe to topics and receive messages for those subscribed topics. It is possible for one consumer to subscribe to multiple topics and also use a regular expression for the topic names. Each consumer is belonged to one consumer group if not created in the default one, and all consumers in the same consumer group split all available partitions of the topic.
“Each partition is polled by only one consumer in that group.” Thus, having consumers more than the number of partitions is not beneficial since extra consumers stay idle. Ensure using group id property to set a specific consumer group rather than using the default one as a practice.
If one application requires all messages of that topic, its consumer should be in a separate consumer group. If one consumer drops out of its group due to exit or crash, a partition rebalance happens and those partitions owned by the lost consumer are assigned to other existing consumers. The same rebalance happens also when the administrator adds new partitions to the topic. During the partition rebalance, all consumers in the group stop consuming messages and wait until it finishes. Consumers maintain membership to the group by sending heartbeats to the group coordinator (broker). Heartbeats are sent automatically when the consumer polls for and retrieves records. If the consumer stops sending heartbeats for long enough, its session will time out and the group coordinator will consider it dead and trigger a rebalance.
Closing a consumer properly ensures to inform the coordinator immediately rather than spending the timeout duration until the coordinator notices the consumer is lost. One consumer in the group (the one first joined initially) is picked as a leader and applies the partition assignment logic after getting the list of all consumers from the coordinator and returns back the assignments to the coordinator, which lets each consumer to know which partitions it will be responsible from.
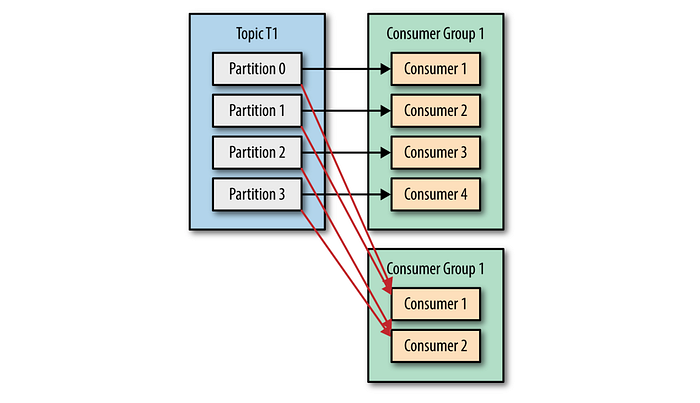
As a caution, you can’t have multiple consumers that belong to the same group running in one thread, and you can’t have multiple threads safely use the same consumer. One consumer per thread is the rule.
Each record received contains: the topic, the partition the record came from, the offset of the record within the partition, and of course the key and the value of the record.
Configuring Consumers
- You can configure the consumer to fetch less times by increasing the min bytes to fetch that helps reducing the load on the brokers in case there are many consumers.
- Yet if you still want to limit the potential latency, you can configure the max wait in ms to fetch new data.
- It is possible to control the maximum number of bytes the server will return per partition to the consumer, but it must be larger than the largest message a broker will accept.
- Since the consumer must call poll() frequently enough to avoid session timeout and subsequent rebalance, the size of the data received shouldn’t be too big to process before the session timeout. If more than the session timeout in ms passes without the consumer sending a heartbeat to the group coordinator, it is considered dead and the group coordinator will trigger a rebalance of the consumer group to allocate partitions from the dead consumer to the other consumers in the group. There should be a balance while picking this duration that will avoid taking too long to detect a failure and unwanted rebalances.
- For the new consumer, it is possible to configure reading the newest records (records that were written after the consumer started running) or reading all the data in the partition starting from the very beginning.
- You can control whether the consumer will commit offsets automatically, or when offsets are committed, which is necessary to minimize duplicates and avoid missing data.
- The maximum number of records that a single call to poll() will return can be controlled to limit the amount of data your application will process in the polling loop.
- The sizes of the low level TCP send and receive buffers used by the sockets when writing and reading data are also configurable. It can be a good idea to increase those when producers or consumers communicate with brokers in a different datacenter with high latency/low bandwidth.
Partitions are assigned to consumers in a consumer group. A partition assignor, given consumers and topics they subscribed to, decides which partitions will be assigned to which consumer. A more advanced option is to implement your own assignment strategy. By default, Kafka has two assignment strategies:
- Range: Assigns to each consumer a consecutive subset of partitions from each topic it subscribes to, however and the number of consumers does not divide the number of partitions in each topic neatly.
- RoundRobin: Takes all the partitions from all subscribed topics and assigns them to consumers sequentially, one by one. In general, if all consumers are subscribed to the same topics, RoundRobin assignment will end up with all consumers having the same number of partitions.
Managing Offsets
Kafka does not track acknowledgments from consumers the way many queues do, instead, it requires consumers committing the last offset read with a special topic to track their position in each partition. After a rebalance, each consumer may be assigned a new set of partitions. In order to know where to pick up the work, the consumer will read the latest committed offset of each partition and continue from there. Committing offsets for the messages not processed can cause losing those in case there is a failure, or processing messages and not committing can cause duplicate processing if the consumer fails.
Managing offsets has a big impact on the client application. If you configure to enable auto commit, then the consumer will commit the largest offset your client received from poll() automatically at every auto commit interval in ms configured. If it is chosen to commit manually, the commitSync() API will commit the latest offset returned by poll(); however make sure you call it after you are done processing all the records in the collection, otherwise you risk missing messages. Throughput can be improved by committing less frequently, but then we are increasing the number of potential duplicates that a rebalance will create. The drawback is that while commitSync() will retry the commit until it either succeeds or encounters a non-retriable failure, commitAsync() will not retry. It’s also possible to commit specified offsets with the same calls.
Summary
This has described how brokers, producers and consumers work together and are configured within the Kafka cluster. Understanding the Kafka internals in-depth is also useful when tuning Kafka for Kafka practitioners i.e.:
- How Kafka replication works
- How Kafka handles requests from producers and consumers
- How Kafka handles storage such as file format and indexes
After this post, I can potentially publish more to follow up for some of these subjects in time: Kafka Internals, Building Data Pipelines (Kafka Connect), Cross Cluster Data Mirroring (MirrorMaker), Administering & Monitoring Kafka, and Stream Processing (Kafka Streams).
Next Up: Kafka Internals
The summary (and illustrations) in this post is based on the book: “Kafka: The Definitive Guide”
